对人来说, 一种理解自然数的方式是数数 (counting)
对计算机来说 (cf. logic.typ), 表示自然数的方式有
- 周期电路
- 算术元件
- 二进制
- 调用自身的函数
然而, 自然数集的元素数量是无限的, 而 bit 和计算机内存是有限的. 人类的记忆也是有限的
空间无限的问题: 现实无法构建空间无限的电路和内存. 即使能, 也受限于电流速度有限
但是可以使用潜在无限的时间来实现 "潜无限"
假设内存的上限无穷但每个周期的内存的占用都有限, 则程序有无限可能的输入, 这也是一种潜无限
然而, 甚至存在集合的元素数量 不可数. Example
- the set of all subset of ,
- all function from to itself,
验证集合论语言的正确性需要 parser, 内存数据结构, 函数. 生成的计算机指令流的实现并不是这个目标范围的重点
集合/类型的动机
-
模块化和乘法分解以简化认知
Example 自然语言的主谓宾 SVO (subject, predicate, object). 假设有 10 个名词和 10 个动词. 假设我们 "忘记了 SVO 规则", 那么, 验证三个词的句子的语法正确性最多需要 次. 如果理解并使用 SVO 规则, 最多需要 次
-
如果集合的元素数量是无限的, 则集合/类型将概念有限化, 使得可以在有限时间内说出来
复杂的 set theory object (集合论对象), proposition (命题) 被储存在变量名里, 所以还是需要人类去检查所有存储在变量名里面的复杂定义, 所以可读性很重要
parser or 证明辅助程序能让人类从需要检阅所有步骤 reduce to 检阅定义 (以及检查编译器的逻辑代码), 跳过大量详细证明步骤, 就能确定证明结果的正确性. 这像 API 的情况
人脑编译器能省略和补充省略, 用容易出错和遗忘来换取临时效率
而且证明辅助还会有其它作用, 类似于, IDE/LSP/友好且互动的编译器错误信息/documentation 时代之前的编程是痛苦的, 数据和信息的组织和结构化和复用做得不好, 也没利用好计算机的强大记忆容量和时间
证明辅助的例子: acornprover
[proposition] proposition 是特殊的 (string, bool) product struct ((字符串, 真假值) 的逻辑乘积结构) 计算机数据结构. 对于数学语言, string field 使用特殊的构造规则来限制, 此 string 限制版本称为 formula (公式)
因为我们无法直接判断一个猜测的真假, 所以我们需要一种具有未定义真假值的语言
from 命题 to 未知命题的, 其真值部分被修改为 (bool, unknow) sum struct
Abbreviation true proposition 和 proposition 经常混用
很多命题是无法被计算机自动推导出来的, 需要人类去寻找可能的路径, 输入到计算机中进行验证, 或者开发更多新的自动化证明方法
我们将假设一些最开始的不需要证明的命题. 以及假设规则之使用现有命题构造新命题
Abbreviation 使用相同的符号 for formula and proposition, " is true/false/unknow",
[formula]
- in (属于)
let symbol (符号) be type of math object, then is a formula
类似于 value : type or variable_name : type in programming language
symbol 不是 math object
- equal (等于)
- and, or, not (且, 或, 非)
let be formula, then
is formula
- forall, exists (所有, 存在)
设 是用 构造的公式 i.e. 在内存中读取 , 使用特殊的函数调用, 则
is formula
- inference (推导) , equivalent (等价) is formula
[equivalent]
等价的一些使用. 对有限的计算机数据来说, 可以穷举证明以下计算结果相等
类似地, 为了表示 "无限元素" 的情况, 定义语言展开或者规定语言转化. 例如无限元素的 De Morgan law
其中 "无限" 的概念有的限化是使用 declare-element-of-set 的符号串
formula, proposition 是内存里特殊的数据结构. 可以认为 math_object, formula, proposition 是编程语言的 type
许多命题是等价的, 于是可以考虑命题的 "quotient" 类型, 但等价可能性是无限的, 是否可能从存在穷举算法, 首先要看它是否 countable …
类似 的冗余, set theory construction rules 也有可能有冗余, 或者说有很多等价的定义方式
规定 (有限的)
transitive :=
transitive :=
follow 有限情况的 bool 的各种规则, 定义语言转换规则: let is formula built with independent/parallel i.e. independent/parallel in memory read and used by specific cuntion, then
[commutative-forall-exists]
same for
[distributive-forall-exists]
(需要假设函数 的存在?)
推导的自然语言例子
下雨了
所以我不会出门
这个例子类似于 conditional branch (条件分支)
let rain : bool;
let out : bool;
match (rain) {
true => out = false,
false => out = undefined,
};
let rain : bool;
let out : bool;
match (rain) {
true => out = false,
false => out = undefined,
};
类似于通常的编程语言的 if block, 在条件不满足时自动跳过执行区
if (rain = true) {
out = false
}
if (rain = true) {
out = false
}
[inference] 对于数学语言, 那就是
- 编译器读取到 formula
- 编译器读取到 formula is true proposition (可能来自定义)
- 编译器读取到 formula is true proposition
- 然后语言规则设置是, 编译器根据这种条件 (来自内存), 赋予 formula 的 bool 值为 true i.e. 设置 is true proposition
[proof] 证明就是编译通过 is true proposition
虽然我对 is always true proposition 这种类型的虚空论证感到很迷惑, 但是没什么理由放弃对某个集合 的局部空集族定义交集, 只好以某种角度去接受, 例如, 不用构造证明就当作是对的所以自动跳过, 或者编程语言中的 if block 的跳过, 没有产生 error …
如果接受这种类型的虚空蕴含, 那么会有
并发现 就是
[reverse-inference] 反向推导. 如果结果是我出门了, 那么肯定不是下雨的结果. 如果条件分支的结果是 out = true, 这不是 rain = true 的结果. 由于理想二进制计算机的 bool 值必定二选一, 所以只能是 rain = false 的结果. 这可以被写为条件分支
match (out) {
true => rain = false,
false => rain = undefined,
};
match (out) {
true => rain = false,
false => rain = undefined,
};
数学上, 反向推导写为 formula , 并定义等价到
[reverse-proof] 反证明就是编译通过 is true proposition
演绎证明还需要三段论 (syllogism)
- 所有生物都会死
- 人是生物
- 所以所有人都会死
其中 "所有生物都会死" 是特殊构造的一种命题
[syllogism] 三段论推导是语言规则
- 编译器读取到 formula is true proposition (可能来自定义 e.g. union))
- 编译器读取到声明 let is true proposition
- 编译器读取到 formula
- 然后编译器根据这种条件 (来自内存) 设置 is true proposition
也即, 编译器根据声明 (可能 "无限") 来实现对数据的具体构造 (有限)
或者理解为, 这种规则和行为就是在定义 这种概念本身
通常也被写为等价的规则 let , then 特殊的推导 formula is always true proposition. 这种形式通常被用于 前面 所说的 "证明就是编译通过 is true proposition"
反向三段论: let , then 等价的 formula is true proposition
我们可能永远不知道一个 bool unknow 的 proposition 是否能被构造性地证明, i.e. 有限步骤编译成功
target proposition 来自哪里? 可能是相关于现实世界的模型
证明需要展开大量句子, 尽管计算机处理 string 是非常快的. 无论如何, 性能优化? 仅在需要时使用 (lazy load)? 两个 proposition 不相互依赖时, 并行 (parallel)? 假设已经证明过的结果 (incremental compilation)?
A proposition has many proofs with different runtime data flow
以下讨论 math-object-construct-rule (数学对象构造规则) alias set-theory (集合论)
从实用的角度来看, 只要逻辑是等价的, 那么就选用最方便最好用的那些, 不需要严格遵循某种已有的框架
[natural-number]
natrual number (自然数) and natrual number set (自然数集) is object. is true proposition
但是计算机无法处理无限. 为了让计算机能用有限的字符和内存去表示自然数集, 把 和 函数作为内存地址里的有限 symbol, 定义以下为 true proposition
等价于用指令流告诉计算机如何连续地 ? 也联系到归纳法
有限的字符的代价是潜在无限的时间, 总是借助了数数或者周期电路
定义语言展开
由于 “定义语言展开” 很长, 因此通常 abbreviated to "definition" "def"
其实 symbol 通常也被用来表示定义语言展开或者规定语言转化. 具体自然数的 可以直接定义为用计算机电路比较内存的值
[declare-element-of-set]
If is non empty (此信息来自 的定义), we can define symbol and construct true proposition (let)
可以构造有限个 declare 语句
[product]
let be set, let is set
表达式 在内存中的数据结构含义应该是清晰的
Abbreviation . in finite case, number of elements
[sum]
let be set then is a set
也称为 tagged union
in finite case, number of element
[function]
let be set. 定义 function space , map as math object 的规则是
or
denoted by
denoted by . in finite case, number of elements
在 prover 中, 函数的定义和行为是, 输入类型 + 输出类型 + 检查到相同输入则规定输出相同
Prop . 将 改为 叫做 normalization of function
[simple-set] alias [type]
将以上简单规则 (product, sum, function) 构造的集合叫做 "simple-set" 或者 "type".
一部分的 "简单" 在于 "每个元素只有一个唯一的 (?) type"
给 type 加上一个命题然后用 logic and 可以得到 "subtype". 代价是失去 "type 的唯一性"
使用 subtype 可以带来很多方便. 虽然实现 subtype 相比只实现 type 需要更多的工作量
也可以认为 subtype 是语法糖, 在任何命题中等价地转换为
其实 "simple-set" 也可能是使用了 "命题约束". 例如 function type, sum type 的定义可以作为 Product type 的 subtype
[set-with-element-in-a-type]
对于 type , 元素类型属于 的集合写为 , 对应到 函数 .
为了减少混淆, 类型的 也用 作为另一记号. 虽然 的使用也被命题判断子集占用了.
空集 对应常值 false 函数. 全集 (通常只写为 ) 对应常值 true 函数.
let (或者写为 ), 定义
只要使用 subtype (以及 dependent type), 集合与类型的区别就变得非常小, 例如, 对于集合 , 对应 subtype (或者写为 , 其中 和 的不同用于区分类型的命题约束和集合的命题约束)
如果证明了一个关于类型 的定理, 有时候, 很容易看出它对某些子集成立. 但是由于将 subset 表示为类型的 subtype 加上了一个命题约束 , 有时 的定理又无法对某些子集成立. 总之, 对于计算机也可能要重新写一次定理. 一种减缓这种繁琐的方法是, 用 typeclass 来表示结构类型及其性质, 使得定理是基于 typeclass 的, 这样就能增加复用, 减少重复
function space 引入了高级别的无限
一件初看反直觉的事情是, 我们似乎知道所有 或所有 , 却无法数出来 cardinal-increase uncountable. 但是, "知道所有 " 究竟是什么意思? 事实上, 试着考虑 "一般方式之找一个 的无限子集" 这一个问题, 就会发现这不是简单的
类似地, 虽然可数已经可以定义一些实数 e.g. , 但如果不借助 subset or map, 可数地构造无法得到全部
下面假设集合属于某个类型
根据 type 定义展开
[subset]
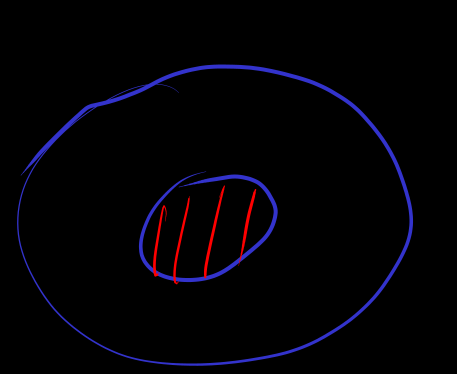
由于 false, 根据虚空蕴含,
denoted by . in finite case, number of elements
let
或者如果 "用类型论构造集合论", 那么集合的相等的定义 reduce to 函数 相等的定义
let
[union]
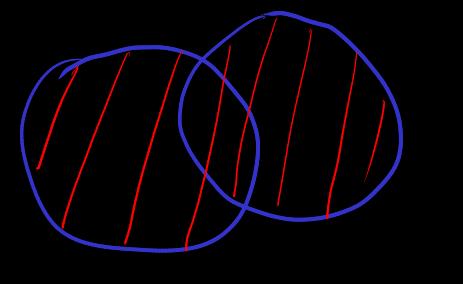
define object 和语言展开
is non-emtpy unless or
[intersection]
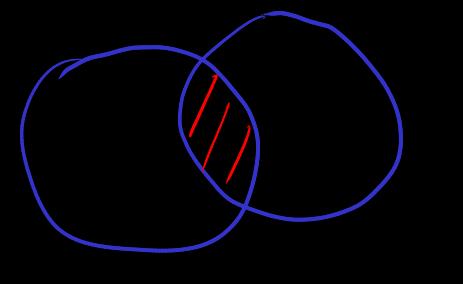
根据虚空蕴含
为什么将 union 和 intersection 限制在 type/set 上? 因为, 由于没有什么理由不去定义空集族的交集并且认为它也是集合, 然而, 如果不限制在 type 上, 如果不对 的集合里面的元素做任何限制, 那么由于虚空论证, 空集族的交集的结果是全集 , 而全集 不是集合, 这破坏了集合论构造规则
空集族的交集是全集的直觉: 因为交集对 是递减的, 从而交集往空集族方向不断增大
根据指标映射 可以定义无限版本的 product, sum
- [product-index]
product component
or
- [sum-index]
sum component
的其它用法
- 内存里的 identifier 的别名
- 内存里的函数返回值. so 应该理解为 add function 的返回值是
[compare-math-lang-with-programming-lang]
数学语言与编程语言非常相似, 都需要编译器检查一系列语言规则
一些区别:
-
一般应用编程语言已经使用了递归, 但数学语言将递归指令本身视为类型. 或者将递归指令称为自然数的递归定义, 或生成自然数的指令. 这使得我们可以讨论一般的自然数, 而无需生成具体的自然数 (由计算机或人脑的周期性电路生成)
-
主流的通用编程语言 (没有自然数集和依赖类型) 仅使用有限次
and,or来生成新类型, 例如struct,enum. 这依赖的是计算机能够表示特定数量的自然数. 另一方面, 数学语言有无限版本的and,or来生成新的类型 (或集合), 例如forall,exists,它们不像有限次的and,or那样表示. 而且 "无限" 甚至可以超越可数的自然数
在底层,数学语言或编程语言都可以用周期电路, 内存位和逻辑门来表示
数学语言从自然数 (以及命题演算和集合论规则) 开始. 例如, 实数是基于自然数定义的. 然而, 它仍然需要 "变量" 的概念, 例如 let a in A 中的 a
通用编程语言从内置类型开始. 从概念, 认知, 应用的角度来看, 最好将它们视为原始概念或计算机内存中的位的结构, 而不是使用数学上的自然数来构造它们
[hierarchy-order-of-set]
以上构造的 set 称为 zero (hierarchy) order set, 或者 zero order type
or
then let be math object, in first order Type
再次使用 object construction rules, 得到的东西也定义为属于
无论如何我们总是可以在编译器中构造这种带有类型和 bool 和各种规则的语言
let be math object, . 诸如此类 …
Example
-
可以被分成多句, 使得可以方便的加入/移除 property, 来得到不同的 struct
(实际上 不是显式必须的, 就像主流集合论不显式必须 那样)
看起来像自然数集 , 所以应该再假设新的 hierarchy 吗? 然后对 , 继续使用 object construct rule … (会导致需要无限的语言规则吗?)
属于 且属于 , 但这两种 "属于" 的语言规则是不同
通常我们不需要显式 hierarchy of Type, 例如, 我们只需要构造 这样的具体类型, 但不需要提到类型 作为元素属于类型
语言是潜无穷的, hierarchy-order-of-Type 语言也是如此. 当然绝大多数编程语言都是潜无穷的
[universal-type]
universal-type 的问题, 或者 type of every type 的问题
这里的容易忽略的一点是, "type of every type" 中的 "type" 指的是什么? 所谓的 "type" 是什么意思? 某种二元变量 bool 函数 or 二元谓词逻辑命题?
从构造性的角度, 需要语言规则去定义一种 "type". 但是, 为了定义 "type of every type", 需要知道所有的构造 "type" 的语言规则. 即使我们知道逻辑门, 周期电路, 内存, 我们也真正不知道所有语言规则或程序, 除非真的写出来 …
即使不考虑 "type of every type", 也能有自指问题. 在数学语言的递归下降构造规则中, math_object type 并不参与在构造规则中. 如果一个类型 T 自指地参与到构造规则中, 则这种语言或程序是非终结的, 例如 T : T, 即使每个周期使用的内存有限, 也无法在有限时间内运行完程序. 注意, 一般的编程语言可以有无限循环 (由不同的原因)
假设程序定义了一种 universal-type 的概念, 且 universal-type 又可以用来构造 "type", 则 universal-type 就自指地参与到了 "type" 的构造规则中, 导致非终结语言或程序
Example [Russell-paradox]
使用 set theory rules 定义
然后让编译器去计算命题
的 bool, 由于
= true, 编译器只计算
的 bool, 然后发现 not 函数, 所以计算 not 里面的 bool, 但这又回到了计算
的 bool, 编译器可能选择进入电路死循环
对于有限集, , 或者无法判断 , e.g. , 因为 , 或者没有定义 这个命题是 true proposition
如果考虑 Type hierarchy, 对于 很可能 从而 因为第一个条件 不满足
似乎当我们想要用 "universal-set" 或者 "universal-type" 时, 我们想要用的是当前类型规则的更高一阶的类型规则
Example [self-referential-paradox] 自指悖论. "这个句子是错的"
this_sentence_is_false : bool = false;
loop {
match (this_sentence_is_false) {
false => this_sentence_is_false = true,
true => this_sentence_is_false = false,
}
}
this_sentence_is_false : bool = false;
loop {
match (this_sentence_is_false) {
false => this_sentence_is_false = true,
true => this_sentence_is_false = false,
}
}
或者用分层绕过自指悖论 (this_sentence = false) = true. 认为它们是不同的句子和判断, 认为它并不能自指
[dependent-distributive]
let be set of sets, let , and let be set of sets, index by its elements
union & intersection
draft of proof: 展开, 使用 distributive-forall-exists
sum & product
[set-minus]

. if then define
[symmetric-set-minus]